����������
���¡�Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks���Ǟ��˸��MFast R-CNN��������ġ������Fast R-CNN�����еĜyԇ�r�g�Dz�����search selective�r�g�ģ����ڜyԇ�r�ܴ��һ���֕r�gҪ���M�ں��x�^�����ȡ�ϡ�(����Fast R-CNN��Ԕ��֪�R��Ո�鿴Fast R-CNN����Ԕ�����x��)Faster R-CNN���Ǟ��Q�@�����}��������ġ�
���˸��õ�����Faster R-CNN�ă��ݣ��ȁ���һ��Faster R-CNN�����w�Y�������D��ʾ :
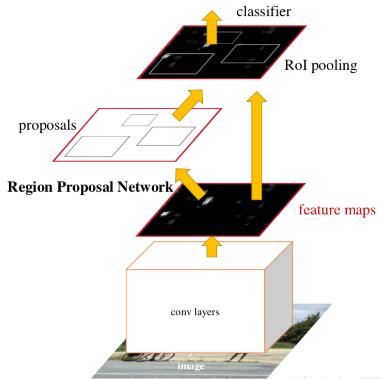
ͨ�^����ɏ��D���Կ���Faster R-CNN���Ă����ֽM�ɣ�
1�����e��(conv layers)��������ȡ�DƬ��������ݔ��������DƬ��ݔ������ȡ���������Q��feature maps
2��RPN�W�j(Region Proposal Network)���������]���x�^���@���W�j���Á�����֮ǰ��search selective�ġ�ݔ���DƬ(����@��RPN�W�j��Fast R-CNN����ͬһ��CNN�������@��ݔ��Ҳ�����J����featrue maps)��ݔ����������x�^���@��ļ������ں���Ԕ����B��
3��RoI pooling����Fast R-CNNһ�ӣ�����ͬ��С��ݔ���D�Q��̶��L�ȵ�ݔ����ݔ��ݔ����Faste R-CNN��RoI poolingһ�ӡ�
4����ͻؚw���@һ�ӵ�ݔ������KĿ�ģ�ݔ�����x�^�����ٵ���ͺ��x�^���ڈD���еľ��_λ�á�
1.RPN
ͨ�^������B����֪����Faster R-CNN�cFast R-CNN���ą^�e���������һ����RPN(Region Proposal Networks)�ľW�j�����T�Á����]���x�^��ģ�RPN���������һ�Nȫ���e�W�j��ԓ�W�j�����M��end-to-end��Ӗ������KĿ���Ǟ������]���x�^�����D��ʾ��
ԭ����RPN�W�j��CNN�����һ��3*3�ľ��e�ӣ��ٽӃɂ�1*1�ľ��e��(ԭ�ķQ�@�ɂ����e�ӵ��Pϵ��sibling)������һ�����Á��osoftmax���M�з����һ�����ڽo���x�^�_��λ��
���@���䌍�Ђ��Ɇ��]���f�����Ҳ���������@ƪ���µ����c��ͨ�^CNN�õ���feature map��ô����ͨ�^RPN�õ��cԭ�D�����ĺ��x�^��ģ��Q��Ԓ�f��RPNݔ���ĺ��x�^���softmax�ĽY����ô�cԭ�D�еą^���M�Ќ����ġ�Ҫ��Q�@���Ɇ��͵�������anchors�ĸ��
2.anchors
anchors���������һЩ�A�O��С�Ŀ�anchors�ķN���k��ʾ����ԭ����k=9����3�N��e(12821282,25622562,51225122)��3�N�L����(1:1,1:2,2:1)�M�ɣ��@��anchors�Ĵ�С�xȡ�Ǹ����z�y�r�ĈD���x���ڙz�y�r������С߅�s�ŵ�600�����߅�����^1000���ҿ�����tf�汾�Ĵ��a��������anchors����
1����ԭ����ʹ�õ���ZF model�У���Conv Layers������conv5��num_output=256����������256�������D(feature maps)�������ஔ��feature mapÿ���c����256-dimensions
2����conv5֮������rpn_conv/3x3���e��num_output=256���ஔ��ÿ���c���ں����܇�3x3�Ŀ��g��Ϣ����ͬ�r256-d��׃
3�����O��conv5 feature map��ÿ���c����k��anchor��ԭ������k=9������ÿ��anhcorҪ��foreground��background������ÿ���c��256d feature�D����cls=2k scores����ÿ��anchor����[x, y, w, h]����4��ƫ����������reg=4k coordinates��scores��coordinates��RPN����Kݔ����
4���a��һ�c��ȫ��anchors��ȥӖ��̫���ˣ�Ӗ��������ں��m��anchors���S�C�xȡ128��postive anchors+128��negative anchors�M��Ӗ��(����ʲô�Ǻ��m��anchors����RPN��Ӗ�����v)
ע�⣬��tf�汾�Ĵ��a��ʹ�õ�VGG conv5 num_output=512g��������512d��������ơ�
3.RPNӖ��
RPNӖ���Ќ������ӱ������нo���ɷN���x����һ���cground truth box������IoU��anchors�������ӱ����ڶ����cground truth box��IoU����0.7���������ӱ������в�ȡ���ǵ�һ�N��ʽ�����ж��x��ؓ�ӱ����cground truth box��IoUС��0.3�Ęӱ���
Ӗ��RPN��loss�������x���£�
L({pi},{ti})=1Ncls��iLcls(pi,p∗i)+��1Nreg��ip∗iLreg(ti,t∗i)L({pi},{ti})=1Ncls��iLcls(pi,pi∗)+��1Nreg��ipi∗Lreg(ti,ti∗)
���У�i��ʾmini-batch�е�i��anchor��pipi��ʾ��i��anchor��ǰ���ĸ��ʣ�����i��anchor��ǰ���rp∗ipi∗��1��֮��0��titi��ʾ�A�y��bounding box�����ˣ�t∗iti∗��ground truth�����ˡ�
���^Fast R-CNN����Ԕ�����x���µĕ��l�F���@���ֵ�loss������Fast R-CNNһ�ӣ�������ؓ�ӱ��Ķ��x��һ�ӣ�������ʾ�rһ�ӵġ�
4.RPN�W�j�cFast R-CNN�W�j�ę�ֵ����
RPN��KĿ���ǵõ����x�^����Ŀ�˙z�y����KĿ���Ǟ��˵õ���K�����w��λ�ú������ĸ��ʣ��@���ֹ�����Fast R-CNN���ġ����RPN��Fast R-CNN����Ҫ������CNN�W�j��ȡ�������������µ�������ʹRPN��Fast R-CNN����ͬһ��CNN���֡�
Faster R-CNN��Ӗ��������Ҫ�֞�ɂ���Ŀ�Ķ���ʹ��RPN��Fast R-CNN����CNN���֣����D��ʾ
-
|



